

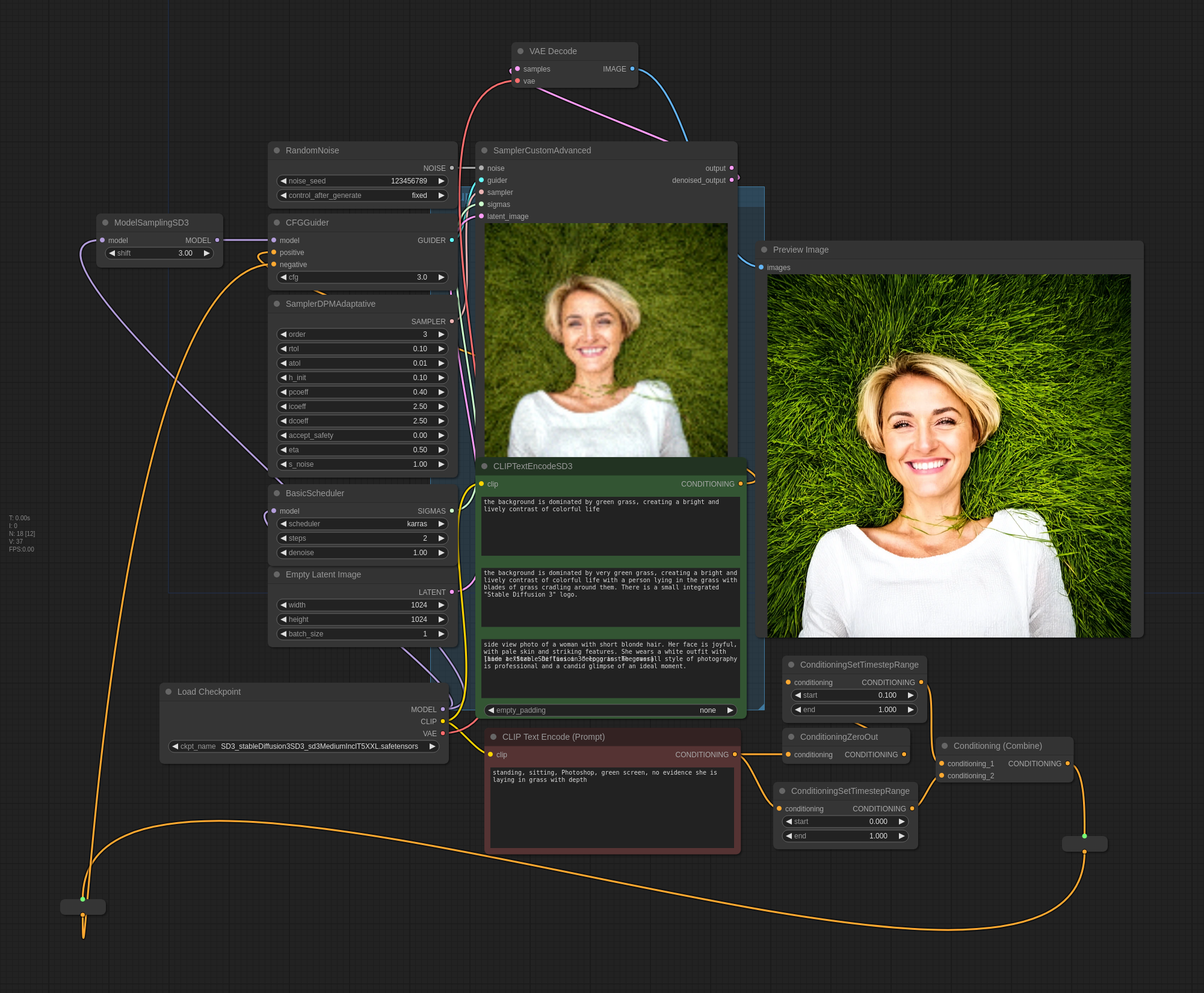
The ComfyUI prompt and workflow is attached to the image: https://files.catbox.moe/s3qufb.png
You can’t copy pasta this prompt. There are a few nodes that are specific to SD3 and required.
EDIT: more proof of the chain that lead to this image. They were not all this good. I'm cherry picking for sure and these are just webp's without workflows attached:











The grass looks like it’s attempting to strangle her LOL
I tried using your workflow, got this LOL

KILL IT WITH FIRE
Your image doesn’t have the workflow for me to have a look. You would need the exact same setup with the unique prompt in all 3 positive positions. I’m not positive my custom sampler setup is fully transferable. If you manually tried to add the prompt, that won’t work. It could be how my GPU generates seeds too. I think there is something I’ve read about that being hardware specific in its determinism.
I edited the post with more of the image set I generated while getting to this one.
I’m out of the loop. What do you mean the workflow is attached to the image? It’s in the image metadata?
ComfyUI embeds the entire workflow (all nodes and connections) inside the metadata of each image. Lemmy wipes all metadata if the instances are hosting the image. I share the original link because that version has the metadata still attached. If you drag it into the Comfy interface it will load up the whole thing automatically.
That’s awesome. In an ideal world all AI gen images would be like that
Is SD3 much better than the good SDXL checkpoints on CivitAI?
No, the version they released isn’t the full parameter set, and it’s leading to really bad results in a lot of prompts. You get dramatically better results using their API version, so the full sd3 model is good, but the version we have is not.
Here’s an example of SD3 API version:

And here’s the same prompt on the local weights version they released:

People think stability AI censored NSFW content in the released model, which has crippled its ability to understand a lot of poses and how anatomy works in general.
For more examples of the issues with SD3, I’d recommend checking this reddit thread.
Thanks, I’m sticking to SDXL finetunes for now. I expect the community will uncensor the model fairly quickly.
I think the difference is typical of any base model. I have several base models on my computer and the behavior of SD3 is quite typical. I fully expect their website hosts a fine tune version.
There are a lot of cultural expectations that any given group around the world has about generative AI and far more use cases than any of us can imagine. The base models have an unbiased diversity that reflects their general use; much is possible, but much is hard.
If “woman lying in grass” was truly filtered, what I showed here would not be possible. If you haven’t seen it, I edited the post with several of the images in the chain I used to get to the main post image here. The post image is not an anomaly that got through a filter, it is an iterative chain. It is not an easy path to find, but it does exist in the base training corpus.
Personally, I think the real secret sauce is the middle CLIP agent and how it relates to the T5 agent.
Not yet. The SD3 checkpoint is too raw and needs a lot of fine tuning. It is also way more complicated with more control variables.
It’s pretty terrible. It feels half baked, and heavily censored.
More over-cooked than half-baked.
Should have left it alone when it worked.
Large or Medium? Any idea when large when be available to download locally?
Medium. I could only get the one with everything packaged to work so far. I tried the one with just the two clip’s packaged, but I only get errors when trying to combine the T5 clip and the other two. I need to get all the pieces separately. Running the T5 in fp16 will likely make a massive difference.
I also need to find a way to read the white paper. I’m not willing to connect to their joke square space website and all of Google’s garbage just to get the paper. I’ll spin up another machine on a guest network and VPN if I need tomorrow. There is a difference between the two clip models and their functionality that I need to understand better and isn’t evident in the example workflows or written about on civitai.
Awesome, thanks so much for the info. It’s a really picture you made!


{kind=link}