
2·
1 day agoThat is a classic. Personally, for the Netherlands, I was thinking some Doe Maar.
Or possibly Little Green Bag, but I’m guessing that doesn’t fit the “relatively unknown outside the Netherlands” criterion, nor is it in Dutch.
That is a classic. Personally, for the Netherlands, I was thinking some Doe Maar.
Or possibly Little Green Bag, but I’m guessing that doesn’t fit the “relatively unknown outside the Netherlands” criterion, nor is it in Dutch.
As @denschub@schub.social always emphasises: make sure to file a report at https://webcompat.com!
We ask everyone to file their reports, because all reports are really useful. Even if we don’t respond to every single thing you report, it’s a signal that we’re processing in many different ways. (…) please, keep reporting all issues you see, because every single blip counts!
https://www.reddit.com/r/firefox/comments/1de7bu1/comment/l8ghtr2/
But also leaving the artist’s signature on an edited comic and not mentioning it’s modified feels shitty too
Removing their signature would be way shittier 😅 And it’s pretty clear that it’s edited anyway.
There’s definitely the bureau kredietregistratie in the Netherlands.
As far as I know you can’t “freeze” it like you describe, though you can request information on what is stored about you and who accessed it. It also costs money to run a check, and credit history doesn’t go back more than five years, doesn’t include your mortgage unless you missed paying that for longer than three months, and doesn’t include debts less than €250.
Edit: also just checked, but the information is only shared with parties that share credit history with the BKR. I think that means that it’s basically frozen by default, i.e. only parties that are actually about to do business with you can access it, but I’m not entirely sure. They’ll at least have to do some kind of business, i.e. not be a generic data broker.

Yeah, and the main difference to me is that that’s not going to sway elections or disclose a journalist’s sources or expose a human rights activist or something like that.
As I understand it, the way it works is that the aggregate categories are defined beforehand, e.g. "these sites are part of the “animals” category. So then if you visit any of those sites, your local install will match them against that list, and then share the aggregation outcome (i.e. “you visited an ‘animals’ site”), without having to share the specific site you viewed - which thus Mozilla can’t even know.

Was also asked about and answered in the recent AMA on reddit:
It’s a bit of a stretch to turn “may also” into “main purpose is”, but you’re right - that shows that indeed it’s not a big leap to use it for advertising.
But no, as I understand it, this isn’t extracting sensitive data from users and then only keeping it in anonymised aggregate form - the sensitive data is handled on your device and never reaches Mozilla, and the anonymised aggregate form (i.e. the high-level category derived from that data) is the only thing that’s actually sent.
And again, it’s always been an ad platform, it’s still the only proven way to fund development.
I won’t comment on this acquisition, cause I have no idea what this company does.
Oh wow, am I dreaming? Is this someone on the internet saying they’re wrong? You’re a rare breed! ❤️
Ah right, we’re talking different definitions of “Firefox users”. I meant that they’re not collecting data on specific users, i.e. there’s nothing on Mozilla servers that says anything about me specifically. The post is talking about Firefox users as a collective, i.e. “this many Firefox users are searching for animals”. Which is something it’s done for ages, albeit not for what websites people are loading. (But it is known, for example, which menu items are most used.)
I’ll also note that that post is not about advertising but about what features to develop, but I’ll grant that it’s not a big leap to use it to serve more granular advertisements as well.
How to free the rest of the web from advertising is not Mozilla’s problem.
It kinds is though, the reason it exists is to ensure the internet is a healthy global public resource.
Some of the many hundreds millions of dollars they’re paid annually in excess of what it costs to maintain a web browser
AFAIK Mozilla nets about $500 million a year from Google being the default search engine, which is roughly the entire budget, and is lower than what Google and Apple spend to maintain their web browsers. So your numbers seem optimistic to me.
Trying to collect data about Firefox users in order to better target ads at them
I haven’t seen that happening, or at least, not “collect” in the sense of “Mozilla has data about Firefox users in order to better target ads at them”. Possibly that the user’s own local device has that data.
Again, Mozilla has always been an ad-funded operation. But also always without doing surveillance.
(I do 100% agree that it is a risky business to be in and that I’d hate to see it cross the line, but I’m withholding judgment until I actually see that happening.)
What’s wrong with differential privacy?
But I suppose this removes any doubt we might’ve had about whether she was keen on continuing Mitchell Baker’s bright idea of turning Firefox into an ad platform.
Unless you insist that Mozilla shouldn’t get funded (or mistakenly think it would not do severely worse if it had a lot less money), then you’d be proposing a pretty big bet to find a different funding source. Essentially, Mozilla is already funded by advertising - on Google, when you use it via Firefox’s default search engine settings.
As for potential alternative sources, donations wouldn’t bring in near the same amount of money, and the subscription business is still nascent (but still proof that advertising isn’t the only thing Mozilla is looking at), and not a guarantee that it would bring in sufficient revenue.
And of course, there’s the question of how to fund the rest of the web. That’s currently advertising, and if that remains the primary funding source, it’d at least be nice if it could be done without extensive surveillance.
Oh ha, ik ken alleen definitie 1 - nr. 2 is een soeplepel. Ik kwam een artikel tegen die zegt dat het in België altijd definitie 2 is, dus wellicht een gevalletje friet vs. patat?
Oh yes, I’m not doubting it would be a multi-year effort, it’s more that I’m not aware of any such effort being in progress. Like, couldn’t the EU at least have set a goal of interoperability in x years?
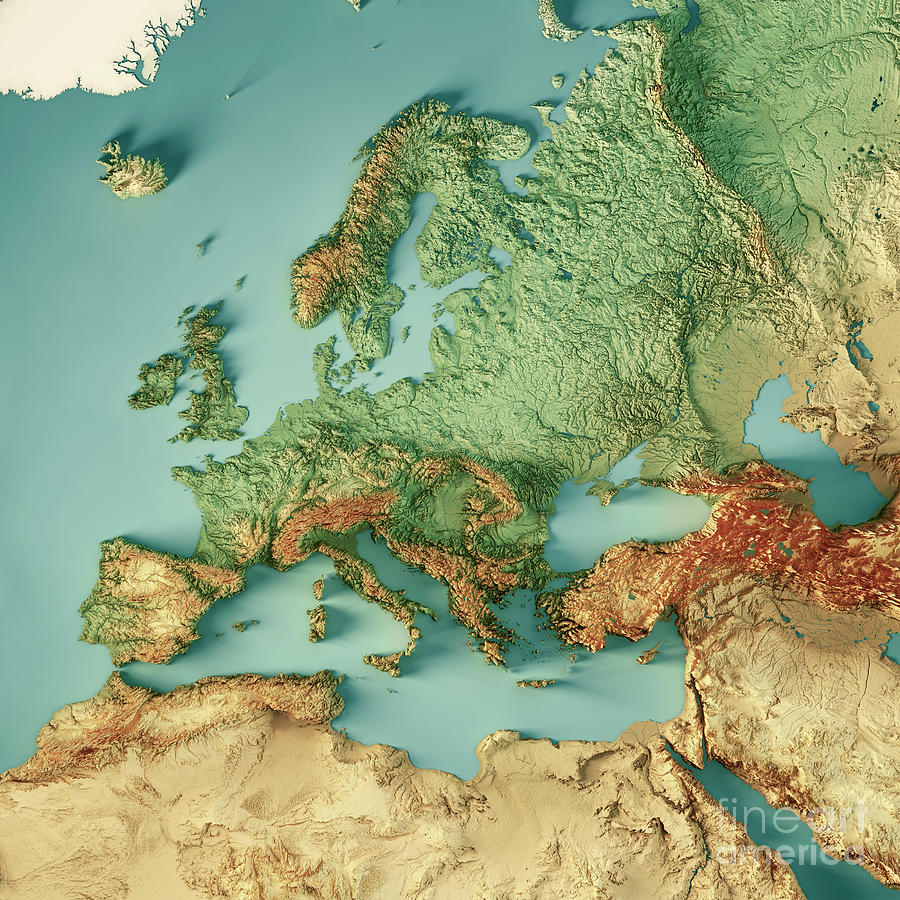
I took a trip from the Netherlands to Romania, and amazingly only had a single transfer.
At least, that was the plan, but then a train went missing on the way there and we had an additional transfer. Pretty stressful. Way home was super smooth though.
The one thing I don’t get the EU doesn’t bring down the hammer on is getting directions and buying tickets. Feels like that should be a relatively easy fix, forcing all European rail companies to align from the top down. But I’m probably unaware of something that makes that harder than it seems.
I wonder if Mozilla was buying time to retract its staff from Russia?
Do you mean firing Russian employees? And preventing other employees from ever travelling to Russia, even for private reasons?
I don’t think that’s very practical 😅

Is dat niet altijd al het geval geweest? Op werk is toch een beetje de verwachting dat je een masker opzet van een braaf persoon. Je zet ook geen foto van een dronken stapavond op je LinkedIn, maar dat is voor mij iig geen reden voor verminderde acceptatie van geheelonthouders.




















{kind=link}
It’s on the roadmap, though I imagine doing it properly is going to take a while - the test build was very rough, just to verify whether it was even realistic.