

Remember in 2004 we all took for granted that as soon as something went online it could never be deleted fully?
I’m at the point that I save a copy of any sufficiently cool image I see online (for art inspo or even if it’s just something that makes me happy) since I’ve lost pictures into the churning froth of twitter by itself after making the mistake of looking away for an hour.
*finds cool thing on any non-FOSS social media app*
Cool, I’ll check this out in a minute or two.
*turning phone screen on later, app shows exactly what I was looking at, perfect to continue where we left off, but then suddenly does loading animation, goes to home page with no way to return to what I was looking at*
Instagram is so bad about this.
I can’t relate because I don’t use phone apps (other than youtube)
Me: well okay, I think it was posted by my friend that I follow, so I’ll check their feed
Me: No? Ugh, that means it was probably posted by the person I follow who posts 40 things an hour, I guess I’ll check their feed.
Me, fifteen minutes later: No… It’s not here either…
Narrator: The original artist deleted the picture thirty minutes ago because crypto-fascists were harassing them for no reason
Yep be your own archive. Every few weeks slap that download folder into a deep storage drive. Name it with basic descriptors.
Oh shit that thing I remembers can’t be found or the site went through enshittification for their IPO or government said something bad. That cool youtube video from 10 years ago has been degraded to 140p …I thought it was in 1080p back then. Thanks gooogle!
Ok to the personal archives. Search well there’s the copies. Lets upload that to whatever is [not shit]
I feel really sad when I can’t find a meme or gif a friend reminds me of because it’s impossible to find even when you remember the title exactly
people thought this? maybe people who didn’t understand how the internet is hosted. by 2004 i had seen several favorite websites shut down.
If it’s cool, it goes offline before the end of the year. If it’s harassing someone, it stays online forever, surviving even nuclear war.
It’s really cool how automated plagiarism bots are basically destroying the artistic and intellectual ecosystem.
Nah, AI is probably the greatest thing that could’ve happened to our ever increasing enshittification of the corporate web. All it’s doing currently is just destroying algorithms that never served genuine content anyway, as neither the algorithms, nor AI, can be used for anything relevant. Google really dug their own hole on this.
I saw the writings on the wall and quit the SEO business two years back because of exactly this reason.
To be beholden on the whims of google is not a foundation to build a business around. If your entire “business” is based on collecting breadcrumbs handed to you from google compared to what they generate on what you do, your business isn’t a business, it’s an employment, to google, without a contract. Where they have every right to fire you at any moment when they see fit.
You’re right, of course, but LLMs also are impacting the entire system of intellectual property that we built so many different systems on. I mean, I always wanted IP abolished, but it’s still funny to me that the capitalists developed an automated tool for destroying their own ability to commodify artistic and intellectual labor.
capitalists aren’t one person though, they all have competing interests
the AI techbro profits while the guy who owns the animation studio fades into obscurity
Right, and these internal contradictions are why capitalism is prone to crisis.
I still think it’s funny.
Ah, who can forget, the landlord, the industrialist, and the financier…
Both exploiting classes, but with different interests… (despite overlap).
Something something enclosure of the commons
Nice take
things zoomers will never experience:
- CO2 levels below 400 ppm
- winter
- hope
- relevant internet search results
You’re thinking of the generation after
Zoomers range from 11-26 years today in the year 2023
A lot of that younger half is just too young to really remember a lot of the stuff they did experience. It’s like how I can’t fully appreciate the pre-internet world, even though I technically grew up in it–because I was only 7 when internet connectivity got big in the US. The internet and other tech still had huge impacts in the 2000s, before this teenagers didn’t have AIM messenger, or texting cellphones, etc.–and I grew up with these things being ubiquitous in my adolescence
But yea the oldest 2 years of that age range is similar to where I am
Idk, man. There was a brief period from, maybe 2002 to 2015, when Google search results were somewhat relevant. This was after the late-80s/early-90s, when web crawlers were a crap shoot at best. And the Alta-Vista / Lycos / AOL / Yahoo era where you could get high profile results reliably but everything else was 50% porn-categories on any conceivable topic.
Even at its peak, Google wasn’t terribly useful outside of the first 10-20 returns. Bing was a flop, until they poached and functionally rebranded as DuckDuckGo. One of the primary appeals of sites like Reddit stemmed from the community oriented information exchange - you could go to a boutique sub on a particular topic and discover sites and content producers you’d never heard of before. Then those sites would gain prominence and start showing up in search engine queries over time. Wikipedia was, similarly, useful in large part because the information was consistent and reliable from month to month and year to year. One of the better things Wikipedia did was to lock down their bigger topics and limit who could post, if for no other reason than it curbed the “newer is better” impulse of modern web traffic engines.
But gaming search engine queries has always been a thing. Bush’s guys figuring out how to get John Kerry’s website to show up when you searched for “Waffles” was a thing back in 2004. Or Steve Lener rigging his Albino Blacksheep site to make “French Military Victories” redirect to a message asking if the user was looking for “French Military Defeats”. Google-bombing has been around since the firm’s inception. Nothing about the above is particularly new or disturbing, save in so far as its a problem these hubs of genius still can’t solve.
Idk, man. There was a brief period from, maybe 2002 to 2015, when Google search results were somewhat relevant.
True, I experienced this and I’m a millennial. Plenty of zoomers did too, but they were just a lot younger I’m guessing it was only perceptible to the oldest ends of their generation group
The google results seemed to really start falling off around 2019 for me
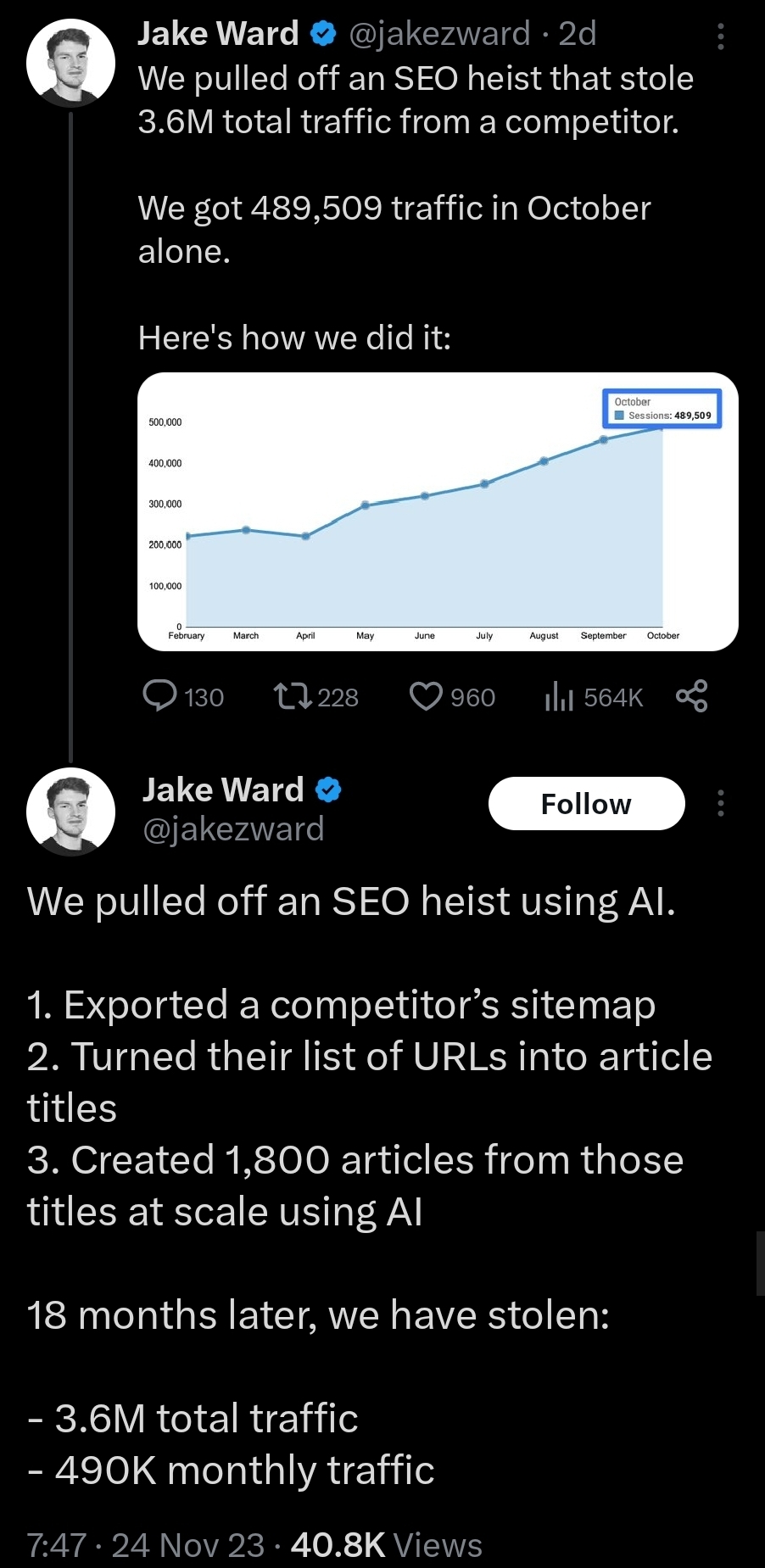
This should for sure be intellectual property infringement… A sitemap of thousands of articles, their own SEO work, put through a plagiarism launderer? And then they publicly admitted they did so. The original site should sue.
This is literally just exactly what SEO people have been doing for the last 15 years.
There is absolutely nothing new here except for using the word “AI” instead of “article spinning”. Which used to be considered blackhat practice lol.
Literally everything in this tweet thread has been standard practice among SEOs for at least 15 years. The change in the quality of the “internet” has occurred because of google getting lax on their standards and algo, not because of the SEOs. Back in the day all the spun articles would either be for niche content nobody was producing much for or it’d be page 2 stuff.
Not defending this shit. Just saying there’s actually nothing notably new in this tweet thread as it’s an area of marketing I actually know very well. Back in the day instead of feeding a competitor’s article into an “AI” and saying “rewrite this article” we used to put it in a spinner and the spinner would rewrite by using thesaurus and heuristics to rewrite paragraphs into new ones. It’d come out a little janky but it worked for serps so meh. That used to all be considered blackhat work but over time Google got lax on it and here we are, now it’s shit.
Generating 1800 articles in a few hours seems like vastly less work than doing the same thing “manually” though.
We weren’t doing it manually. It was just lower quality. Article spinning was always an automated process.
deleted by creator
Yeah this is literally just an ad for the AI article-writing service this guy runs - and honestly I could imagine a lot of marketing shops are trying to run the same thing with just OpenAI API calls already, it looks like his prompt is just “Write an article based on this URL”, which is pretty garbage considering there’s more sophisticated ways at milling out bullshit like this.
What’s the purpose of all this though?
making advertising money and maybe tricking a few suckers into using your Amazon affiliate link
Article pages that run ads. And building networks of high ranking high trust pages that can be used to link to other things for transferring trust. Ranking other stuff highly too
deleted by creator
Man I’m so glad I’m on the good internet™️ and not the bad one
Xi please let me hop over the great firewall.
Using the phrase “SEO Heist” is a gulagable offense.

Cyberpunk 2077 stop being correct about everything challenge (Rache Bartmoss edition)
I would kill for a real life Datakrash.
Please someone end the internet.

The point of the Datakrash story is Bartmoss was wrong and just turned an essential infrastructural backbone into something utterly hostile to humanity and allowed all the corporations to set up their own propietary nets they have even tighter control over. Same thing would happen irl
Admittedly yeah that would happen but arguably (and optimistically) it’d be a better environment to isolate networks away from corps.
Fictitious Capital on steroids
holy shit i love living in the best of all possible worlds so fucking much dude
Death to America
🎵So many possible worlds, but we’ve got this one🎶
Retvrn to webrings
It’s so cynical and short sighted. The byproduct of referring to everything online as “content” without caring about what that content is. Their “how to bake a pie” example only makes sense if you don’t care about how to bake a pie. Short sighted because if the “content” is LLM garbage then google or w/e can easily just generate the output. Like if their example was “tensorflow optimization” there’s no way the coders would be like “yeah, that’s perfect. The robot will teach me.” Because they understand that LLMs give wrong information, they just assume that baking a pie is unworthy of real actual instruction. Ironically, I think the coder-tech-help-blog space is actually where you can generate nonsense content and get clicks.
good, Google sucks





















{kind=link}