You must log in or register to comment.
That wasn’t the design engineer’s fault. It was the design engineer’s fault and the QA tester’s fault and management’s fault.
Also…I blame society.
I blame reddit
I blame society for reddit.
Fuck Ajit Pai
Plus the government
It’s funny to me when people act like this is some weird take but at the same time call every layer of management above the workers “leaders”. If leaders aren’t responsible for anything then what purpose do they serve?
I once got a funny look at a job interview when I implied managers should do their job. It was a pretty clear indication that I don’t want to work there and I think my response also crossed me off their list.
And marketing, and sales. Tons of people would have pointed this out.
Some small committee of managers would have come up with some reason to dismiss all of these complaints.
Also there’s a very simple workaround for this that doesn’t require a full recall.
And what is going on 4 ports to the right? Seems like a similar problem.
And marketing, and sales. Tons of people would have pointed this out.
Maybe, but (unlike QA and management) I wouldn’t expect them to notice the problem or hold them responsible for failing to do so.
Marketing (or “product management” or whatever your org calls them) should be creating the requirement docs which the engineers implement. Sales should be learning and using every aspect of the product. Oh I forgot to mention tech docs/pubs, throw them in there too.
So yeah, this isn’t just “some engineer” and QA. A ton of people would have fucked up.
And what is going on 4 ports to the right? Seems like a similar problem.
The mini-USB console port? Yeah, that could be a similar issue, but I’ve never had to use that port while a device is in active production. If I can’t access the device via IP on our management fabric, the device is probably in a broken-enough state that I can probably unplug a cable or two to attach a laptop and troubleshoot.
I guarantee management was rushing this product out the door to meet deadlines without adequate testing and without running a pilot program. That’s the only way this could realistically happen.
I suspect this one falls squarely on management. But I bet they didn’t take the blame.
Incan imagine many reasons to have done this on purpose
how many bad raises to the center of a tootsie pop
Right up there with the classic Macintoshes with unshielded speakers nested right up against the hard drive and would periodically emit a tone that would reboot the computer.
My personal favorite was the early-90s Macs that didn’t have an eject button for the floppy drive, but did have a pushbutton power switch … directly above the floppy drive. It took me weeks to stop powering off the computer every time I wanted to eject the floppy. Silly me, not picking up on the oh-so-very-intuitive practice of dragging the floppy icon over to the trash can in order to eject it.
Also extra fun was if the computer was non-functional and had a floppy disk in it, since it required working software in order to eject the disk, you had to do some disassembly in order to retrieve the disk.
Which computer was that? I had a bunch of early apples and Macs, and they all had a little paper clip hole to manually eject the floppy
Was that the same mac that had an officially sanctioned maintenance drop of 5cm to combat socket creep?
That would be the Apple III
Wait you had to drop it 5 cm so it would knock something back into place?
I don’t remember all the details, but that’s the gist of it, yes.
A common problem with 80’s computer designs was socket creep - thermal expansions and contractions would cause chips and cards to gradually climb out of their sockets and slots over time, and this was very prevalent on one of the macs of ye olden days.
The official response when asked about this issue was to lift the computer a few cm off the desk and drop it back down to let everything reseat properly.
EDIT: Thanks to @fury@lemmy.world for providing additional info. See his response for more detail
Hard drive pin that needed to return to home position for the machine to boot would stick. A small drop would allow the spring to push it back home, and the drive would return to function.
Got the same energy as “wrap your Xbox in a towel to let the heat resolder the broken connections”.
We should really just let people open their own hardware to easily fix this stuff.
I know what all of those words are but I don’t understand what this is referring to and I can’t find anything in a web search. Can you elaborate?
The Apple III
That sounds like planned obsolescence as the speaker slowly rots the bits spinning nearby
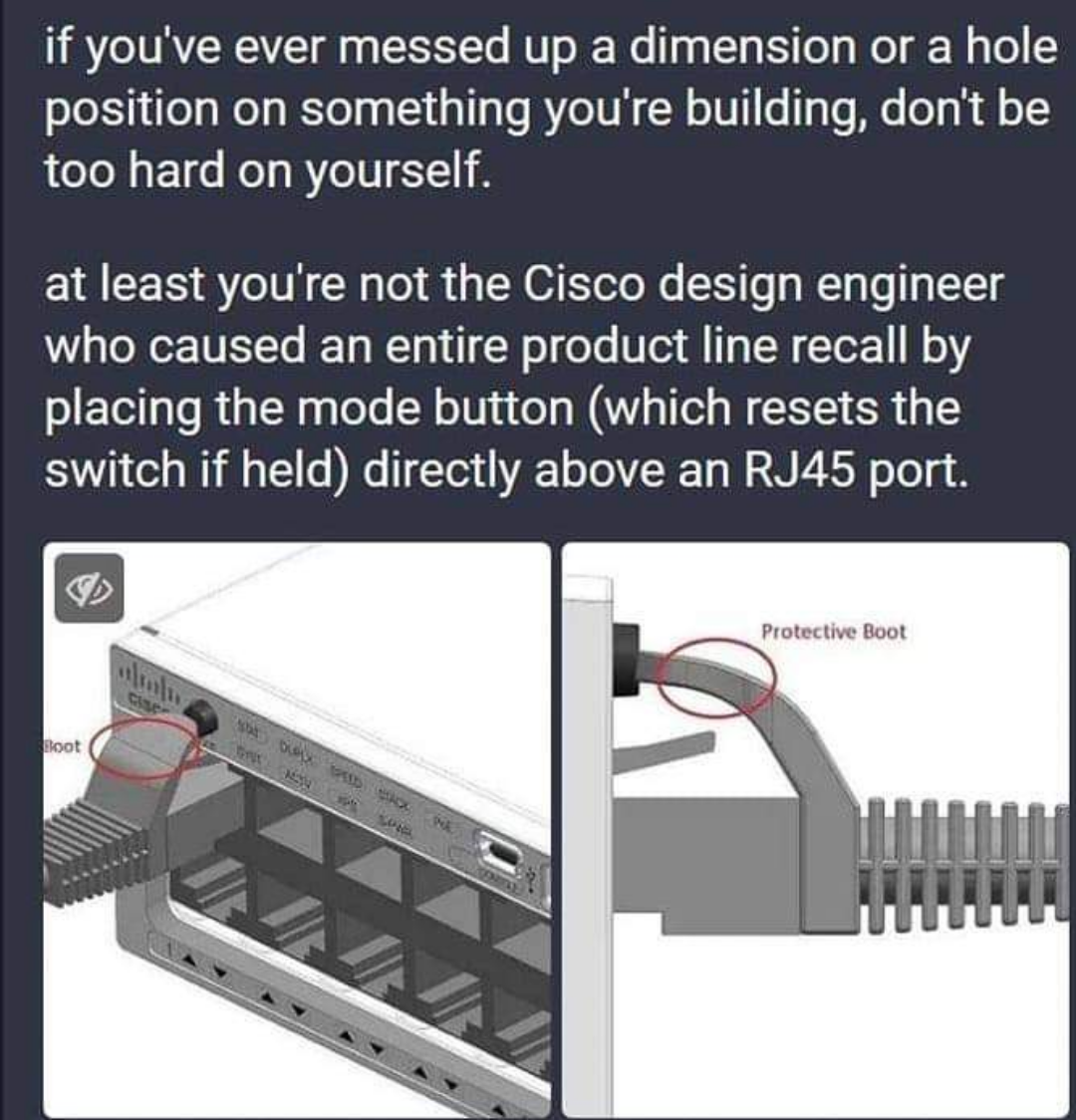
How the actual fuck did this get through QA and production?
The protective boot is optional on the RJ45 CAT5/6 specification. I suspect they likely didn’t test with all the different RJ45 variants dongles.
If the client has enough money for Cisco hardware they can definitely afford the boogie RJ45 with Booties.
Bougie, unless they’re just funky as fuck.
i read it exactly as it was written and now I’m imagining RJ45s in an earth wind and fire music video
QA budget is real low. They can only afford the ones that are bare copper stuffed into a RJ45.
If they’re lucky a DIY job with no exposed pairs outside the RJ45
How did the design make it past quality control, though? Sounds like a few balls were dropped.
QC probably tested with normal cables, not the protective jacket ones.
That’s pretty shitty QC, but perfectly believable.
They’re is no QC that’s how.
Just to clarify something… they say it “resets the switch” but some people may not realize in Cisco parlance, that means factory reset, as in wipe it completely and start with a fresh config. It was WAAAY worse than just rebooting it.
When Express Setup is inadvertently invoked by the protective boot of the cable, these messages are seen in the syslog:
%SYS-7-NV_BLOCK_INIT: Initialized the geometry of nvram
%EXPRESS_SETUP-6-CONFIG_IS_RESET: The configuration is reset and the system will now reboot
%SYS-5-RELOAD: Reload requested by NGWC led process. Reload Reason: Reload command.
%STACKMGR-1-RELOAD_REQUEST: 1 stack-mgr: Received reload request for all switches, reason Reload command
%STACKMGR-1-RELOAD: 1 stack-mgr: Reloading due to reason Reload command.
After this occurs, the device resets. The startup configuration is erased once the device enters Express Setup.
I almost found this out the hard way. I think on the Cisco equipment, it’s something like: Hold for 2 seconds to cycle power. Hold for 5 seconds to wipe config.
Our IT guy nearly had a heart attack when, over the phone, I asked if I should press the little “Reset” on the back.
That couldn’t have been an accident, they wanted people to suffer.
there’s a saying, never attribute malice when incompetence would do. I don’t think an engineer would do this on purpose, but it really should have been caught by QA.
Found one of these at work one day. It’s equally hilarious in person
I would love to see one of those IRL
He should be a dildo designer.
Hehehehe
But really he put the button there rather than the button pusher.
And that design engineer’s name? Pagliacci
But doctor… I am the ethernet cable.
Doctor? I thought you were this ship’s doctor!
how common are those specific types of cables? The ones with that specific “protective boot”
Really common with quality premade cables.
You know, the ones used in datacenters
Yeah every one of my Ethernet cables at home have that.
Almost every Ethernet cable has this, you can search for RJ-45 cables on Amazon and you will basically always see something like this.
Very. While the specific length and position of the protective varies between brands, the concept is very common in high-end premade cables. All of the premade RJ45s I use at work have it. The purpose is so that you can pull the cable in one end without the plastic clip snagging in some other cable and breaking.
I’ve seen some really cheap ones that don’t have it. But the vast majority of cables like that I’ve seen have the protective boot.
Basically all of them
I believe it’s part of the standard so, all of them. Unless you get your cables from some cheap Chinese knockoff brand, but I don’t imagine that any business would do that. Not worth the risk.
Pretty charitable calling that fucking flipper a ‘boot’, I must say.
deleted by creator
deleted by creator
Hate to be that guy, but for something bad like this to happen, it’s never one person’s fault. Like the engineer who nuked the gitlab backup by mistake while production had been deleted. He didn’t lose his job and rightfully so, there were a thousand other issues that led to that.
Recently, YouTube started adding a tracking parameter to their share URLs, when using the “share” button on a video. With this, they can track who is sharing videos with who, and under some circumstances even how they are shared. The tracker starts with the question mark in the link you posted and the link works perfectly fine without that part.
Haha!











{kind=link}