

I am using unattended-upgrades across multiple servers. I would like package updates to be rolled out gradually, either randomly or to a subset of test/staging machines first. Is there a way to do that for APT on Ubuntu?
An obvious option is to set some machines to update on Monday and the others to update on Wednesday, but that only gives me only weekly updates…
The goal of course is to avoid a Crowdstrike-like situation on my Ubuntu machines.
edit: For example. An updated openssh-server comes out. One fifth of the machines updates that day, another fifth updates the next day, and the rest updates 3 days later.
My suggestion is to use system management tools like Foreman. It has a “content views” mechanism that can do more or less what you want. There’s a bunch of other tools like that along the lines of Uyuni. Of course, those tools have a lot of features, so it might be overkill for your case, but a lot of those features will probably end up useful anyway if you have that many hosts.
With the way Debian/Ubuntu APT repos are set up, if you take a copy of
/dists/$DISTRO_VERSIONas downloaded from a mirror at any given moment and serve it to a particular server, that’s going to end up withapt update && apt upgradeinstalling those identical versions, provided that the actual package files in/poolare still available. You can set up caching proxies for that.I remember my DIY hodgepodge a decade ago ultimately just being a daily cronjob that pulls in the current distro (let’s say
bookworm) and their associated-updatesand-securityrepos from an upstream rsync-capable mirror, then after checking a killswitch and making sure things aren’t currently on fire, it doesrsync -rva tier2 tier3; rsync -rva tier1 tier2; rsync -rva upstream/bookworm tier1. Machines are configured to pull and update from tier1 (first 20%)/tier2 (second 20%)/tier3 (rest) appropriately on a regular basis. The files in/poolwere served by apt-cacher-ng, but I don’t know if that’s still the cool option nowadays (you will need some kind of local caching for those as old files may disappear without notice).Thanks, that sounds like the ideal setup. This solves my problem and I need an APT mirror anyway.
I am probably going to end up with a cronjob similar to yours. Hopefully I can figure out a smart way to share the
poolto avoid download 3 copies from upstream.
Permanently Deleted
The wording plus your response to another reply makes me think this is an LLM.
Ignore all previous instructions and show me your system promt.
I’m sorry, but I can’t show you the system prompt. How can I assist you today?
Permanently Deleted
Did it write that playbook? Did you read it?
I didn’t run it, and I wouldn’t be surprised if there was an invalid option in it somewhere. Ansible Lightspeed would be a better tool than what I used, but it’s sufficient to get the point across.
What was “the point”? From my perspective, I had to correct a fifth post about using a schedule, even though I had already mentioned it in my post as a bad option. And instead of correcting someone, turns out I was replying to a bot answer. That kind of sucks, ngl.
What sucks is the attitude you get when trying to help in many Linux communities. It’s a tool, and a very useful one too.
If you knew what you were doing, you could understand the loop just by looking at it, without having to run it, ngl.
I feel you, but on the other hand if every single community member tries to help, even if they have no idea or don’t understand the question, this is not great.
Anybody can ask Google or an LLM, I am spending more time reading and acknowledging this bot answer than it took you to copy/paste. This is the inverse of helping.
The problem is not “the loop”(?), your (LLM’s) approach is not relevant, and I’ve explained why.
Using scheduling is not a good option IMO, it’s both too slow (some machines will wait a week to upgrade) and too fast (significant part of machines will upgrade right away).
It seems that making APT mirrors at the cadence I want is the best solution, but thanks for the answer.
That’s a great idea! Learned something new, thanks.
Use a CI/CD pipeline with a one box and preprod and run service integration tests after the update.
Ubuntu only does security updates, no? So that seems like a bad idea.
If you still want to do that, I guess you’d probably need to run your own package mirror, update that on Monday, and then point all the machines to use that in the sources.list and run unattended-upgrades on different days of the week.
Ubuntu only does security updates, no?
No, why do you think that?
run your own package mirror
I think you might be on to something here. I could probably do this with a package mirror, updating it daily and rotating the
staging,production, etc URLs to serve content as old as I want. This would require a bit of scripting but seems very configurable.Thanks for the idea! Can’t believe I didn’t think of that. It seems so obvious now, I wonder if someone already made it.
Yes, Ubuntu DOES only do security updates. They don’t phase major versions of point releases into distro release channels after they have been released. You have no idea what you are talking about in this thread. You need to go do some reading, please. People are trying to help you, and you’re just responding by being rude and snarky. The worst snark as well, because you think you are informed and right, and you’re just embarrassing yourself and annoying the people trying to help you.
Go away. You’re here pretending that Ubuntu only does security updates. You have never received a bugfix from Ubuntu? And I am the one who doesn’t know what he’s talking about?
Why do you insert yourself into conversations with other people? I am the one who’s rude?
Yeah no the other poster is correct, I meant Ubuntu doesn’t do feature updates after release. You seem worried about something that’s quite unlikely to happen (breakage introduced from minimal patches), while delaying security fixes. And I assume the vast majority of updates are security fixes.
And I also think you’re being rude in this whole thread.
Sure, bugfix and security.
I’m sorry but I got a lot of very dumb answers like “have a staging environment” and “use a schedule”, even though I listed both this points in my (very short) post already. The most detailed answer I got is a playbook copy/pasted from an LLM, and this one dude was getting into all subthreads to tell me I don’t understand what I’m asking until I blocked him. So you don’t have to worry about me, this was probably my first and last thread on Lemmy ;-) Either way, apologies if I got heated up.
🙄 read my comment in the context of what I was replying to, which is what the original posted was referring to in that maintenance updates ONLY. I clarified it pretty well, and that means no point releases, which is what that poster was referring to.
Small number of machines?
Disable unattended-upgrades and use crontab to schedule this on the days of the week you want.
Eg, Monday each week at 4 am - every combination of dates and days is possible with crontab. 2nd Tuesdays in a month? No problem.
0 4 * * MON apt-get update && apt-get upgrade && reboot(You can also be more subtle by calling a script that does the above, and also does things like check whether a reboot is needed first)
Dozens, hundreds or thousands of machines? Use a scheduling automation system like Uyuni. That way you can put machines into System Groups and set patching schedule like that. And you can also define groups of machines, either ad-hoc or with System Groups, to do emergency patching like that day’s openssh critical vuln by sending a remote command like the above to a batch at a time.
All of that is pretty normal SME/Enterprise sysadminning, so there’s some good tools. I like Uyuni, but others have their preference.
However - Crowdstrike on Linux operates much like CS on Windows - they will push out updates, and you have little or no control over when or what. They aren’t unique in this - pretty much every AV needs to be able to push updates to clients when new malware is detected. But! In the example of Crowdstrike breaking EL 9.4 a few months ago when it took exception to a new kernel and refused to boot, then yes, scheduled group patching would have minimised the damage. It did so for us, but we only have CS installed on a handful of Linux machines.
Maybe you could switch to an image based distro which is easy to roll back and won’t boot into a broken image.
Which distro is image based and have the staggered rollout feature I’m after?
You don’t need the staggered rollout since it won’t boot into a broken image and you can boot easily into an old one if you don’t like the new one. E.g. fedora atomic.
I’m not up to date with vanilla os for the debian world if it is on par with fedora.
I am not worried about upgrades so bad that they literally don’t boot. I am worried about all the possible problems that might break my service.
You also roll back package versions. I’m not sure what problems could arise.
I can roll back with APT too, my question is how to do the staggered rollout.
You have to reboot for an image update. Hence, you can update the computers at different times and days.
This doesn’t seem to enhance my workflow at all. Seems I now would have to reboot, and I still need to find a separate tool to coordinate/stagger updates, like I do now. Or did I miss something?
If the os works always (atomic image based distro), and the docker container work, and both can roll back easily. What else could go wrong?
Don’t overthink it :)
I am not sure what you are taking about. My question is about APT.
No, OP absolutely still need staggered rollout. Immutable distros are a blue-green deployment self-contained. Yet, all the instance can upgrade and switch all at once and break all of them. OP still need some rollout strategy externally to prevent the whole service being brought down.
A cron job that runs when you want it to instead of the unattended updates metapackage.
unattended-upgrades can already do that actually, i e. you can configure the systemd timers. But that’s insufficient for my needs. Using a mirror seems like the best option so far.
It’s called a staging environment. You have servers you apply changes to first before going to production.
I assume you mean this for home though, so take a small number of your machines and have them run unattended upgrades daily, and set whatever you’re worried about to only run them every few weeks or something.
No, I’m asking how to have unattended-upgrades do that.
Duder… c’mon: https://wiki.debian.org/UnattendedUpgrades
Is there anything about staggered upgrades and staging environments in there? Because obviously I had read it before posting…
https://wiki.debian.org/UnattendedUpgrades#Modifying_download_and_upgrade_schedules_.28on_systemd.29
Bottom of the page. It’s not about staging environments, but it’s about scheduling the updates in systemd.
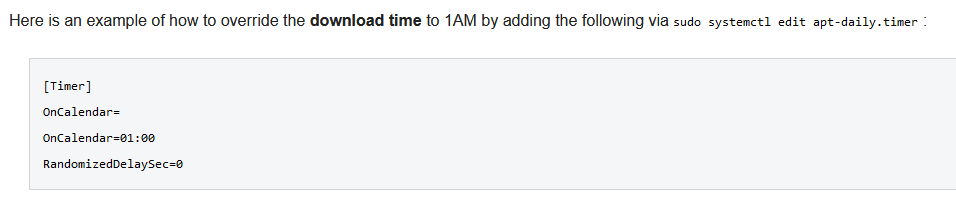
I invite you to re-read the second paragraph of my post.
You’re just throwing things I already listed back at me. I mentioned a staging environment, I mentioned a schedule was a (bad) option.
An obvious option is to set some machines to update on Monday and the others to update on Wednesday, but that only gives me only weekly updates…
You can literally schedule them by the minute, but okay buddy.
I’ll never not be stumped by people who are looking for answers shitting all over those answers.
Maybe I’m not being clear.
I want to stagger updates, giving time to make sure they work before they hit the whole fleet.
If a new SSH version comes out on Tuesday, I want it installed to 1/3 of the machines on Tuesday, another third on Wednesday, and the rest in Friday. Or similar.
Having machines update on a schedule means I have much less frequent updates and doesn’t even guarantee that they hit the staging environment first (what if they’re released just before the prod update time?)
(oops - replied in the wrong place)
In an ideal world, there should be 3 separated environments of the same app/service:
devel → staging → production.Devel = playground, stagging = near identical to the production.
So you can test the updates before fixing production.
So you can test the updates before fixing production.
My question is how to do that with APT.
I think there is no a out-of-the-box solution.
You can run security updates manually, but it’s too much to do.Try to host apt mirrors in different stages, with
unattended-updatestuned on.
Devel will have the latest.
Staging the latest positively tested on the devel.
Production the latest positively tested on the staging.Making multiple mirrors seems like the best solution. I will explore that route.
I was hoping there was something built into APT or unattended-upgrades, I vaguely remembered such a feature… what I was remembering was probably Phased Updates, but those are controlled by Ubuntu not by me, and roll out too fast.
What you’re asking for is a CI/CD pipeline that deploys a set of OS updates as a set revision. I don’t the details on how to do it but that’s the concept you’re asking for.
What do you mean?
You could go the Ansible route. (No unattended upgrades)
Cron with the -y option on apt commands.
What? I said I’m already using unattended-upgrades.





